![[Profile picture of Ruben Verborgh]](/images/ruben.jpg)
Chapter 3 – Semantics
Into this house we’re born
Into this world we’re thrown
Like a dog without a bone
An actor out on loan The Doors, Riders on the Storm (1971)
Since machines cannot fully interpret natural language (yet), they cannot make sense of textual content on the Web. Still, humans are not the only users of the Web anymore: many software agents consume online information in one way or another. This chapter details the efforts of making information machine-interpretable, the implications this has on how we should publish information, and the possibilities this brings for intelligent agents. We then discuss whether semantics are a necessity for hypermedia.
It didn’t take long for machine clients to appear, as the Web’s excellent scalability led to such tremendous growth that manually searching for content became impossible. In 2008, Google already gave access to more than 1 trillion unique pieces of content through keyword-based search [2]. Lately, the search engine started focusing on giving direct answers to a query instead of presenting links to webpages that might provide those answers [21]. Search engines started emerging, indexing the content of millions of webpages and making them accessible through simple keywords. Although various sophisticated algorithms drive today’s search engines, they don’t “understand” the content they index. Clever heuristics that try to infer meaning can give impressive results, but they are never perfect: Figure 2 shows an interesting case where Google correctly answers a query for paintings by Picasso, but fails when we ask for his books. If we want machines to do more complex tasks than finding documents related to keywords, we could ask ourselves whether we should make the interpretation of information easier for them.
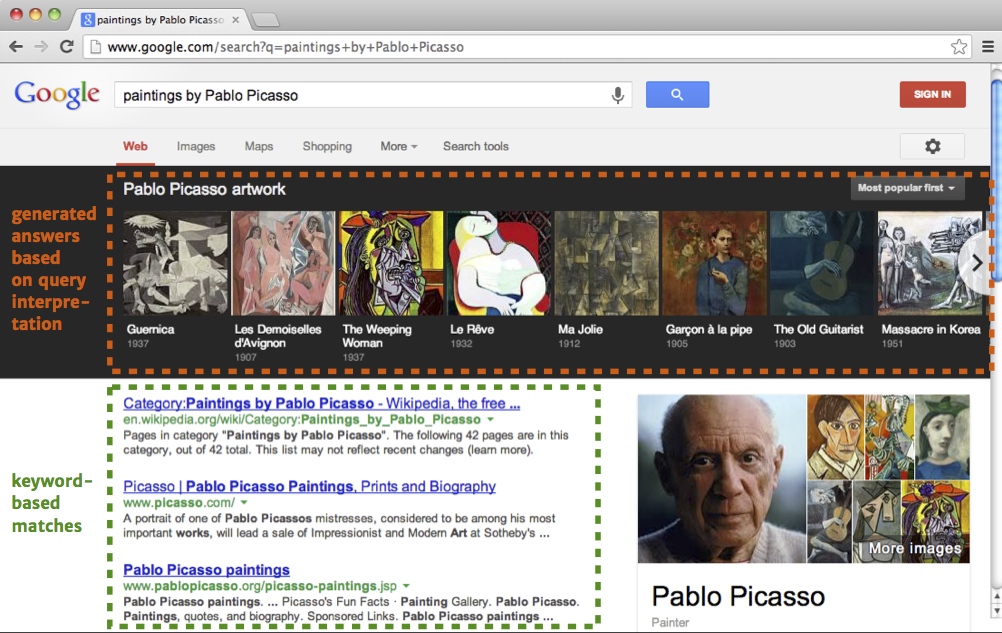
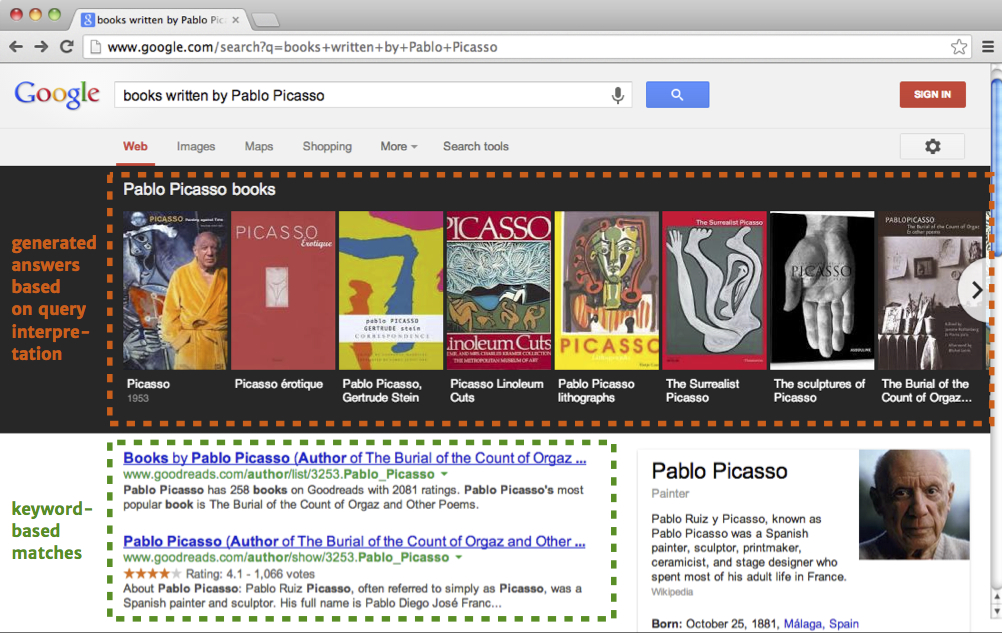
Figure 2 – In addition to offering the traditional keyword-based matches, Google tries to interpret the query as a question and aims to provide the answer directly. However, machine-based interpretation remains error-prone. For instance, Google can interpret the query “paintings by Pablo Picasso” correctly, as it is able to show a list of paintings indeed. The query “books written by Pablo Picasso” seemingly triggers a related heuristic, but the results consist of books about—not written by—the painter; an important semantic difference.
The Semantic Web
The original article starts with a futuristic vision of intelligent agents that act as personal assistants. At the 2012 International Semantic Web Conference, Jim Hendler revealed this angle was suggested by the editors, and then jokingly tested how much of this vision was already being fulfilled by Apple’s Siri (which promptly failed to recognize his own name). The idea of adding semantics to Web resources was popularized by the now famous 2001 Scientific American article by Tim Berners-Lee, Jim Hendler, and Ora Lassila, wherein they laid out a vision for what they named the Semantic Web. Perhaps the most important starting point is this fragment [12]:
The Semantic Web is not a separate Web but an extension of the current one, in which information is given well-defined meaning, better enabling computers and people to work in cooperation. Tim Berners-Lee et al.
The Web already harbors the infrastructure for machines, as explained in the previous chapter when discussing the REST architectural style. However, there’s only so much a machine can do with structural markup tags such as those found in HTML documents: the data can be parsed and transformed, but all those tasks require precise instruction if there is no deeper understanding of that data. Compare this to processing a set of business documents in a language you don’t understand. If someone tells you how to classify them based on structural characteristics, such as the presence of certain words or marks, you might be able to do that. However, this strategy fails for documents that are structured differently, even if they contain the same information.
Knowledge representation
A first task of the Semantic Web is thus knowledge representation: providing a model and syntax to exchange information in a machine-interpretable way. The Resource Description Framework (RDF) [28] is a model that represents knowledge as triples consisting of a subject, predicate, and object. The XML serialization of RDF used to be the standard, but its hierarchical structure is often considered more complex than Turtle’s triple patterns. Different syntaxes exist; the Turtle syntax [4] expresses triples as simple patterns that are easily readable for humans and machines. Starting from a basic example, the fact that Tim knows Ted can be expressed as follows in Turtle.
:Tim :knows :Ted.
This is a single triple consisting of the three parts separated by whitespace, :Tim (subject), :knows (predicate), and :Ted (object), with a final period at the end. While a machine equipped with a Turtle parser is able to slice up the above fragment, there is not much semantics to it. To a machine, the three identifiers are opaque and thus a meaningless string of characters like any other.
Just like on the “regular” Web, the trick is identification: if we use URLs for each part, then each concept is uniquely identified and thus receives a well-defined interpretation.
<http://dbpedia.org/resource/Tim_Berners-Lee>
<http://xmlns.com/foaf/0.1/knows>
<http://rdf.freebase.com/ns/en.ted_nelson>.
As we’ve seen in the last chapter, a URL identifies a conceptual resource, so it is perfectly possible to point to a person or a real-world relation. But how can we represent a person digitally? We can’t—303 See Other [23]. The differentiation between non-representable and representable resources has been the subject of a long-standing discussion in the W3C Technical Architecture Group [7].
In the above fragment, the identifiers have been replaced by URLs which correspond to, respectively, Tim Berners-Lee, the concept “knowing”, and Ted Nelson. This is how meaning is constructed: a concept is uniquely identified by one or more URLs, and a machine can interpret statements about the concept by matching its URL. If a machine is aware that the above URL identifies Tim Berners-Lee, then it can determine the triple is a statement about this person. If it is also aware of the “knows” predicate, it can determine that the triple means “Tim Berners-Lee knows somebody”. And of course, comprehension of Ted Nelson’s URL implies the machine can “understand” the triple: Tim has a “knows” relation to Ted—
Since URLs appear a lot in RDF fragments, Turtle provides an abbreviated syntax for them:
@prefix dbp: <http://dbpedia.org/resource/>.
@prefix foaf: <http://xmlns.com/foaf/0.1/>.
@prefix fb: <http://rdf.freebase.com/ns/>.
dbp:Tim_Berners-Lee foaf:knows fb:ted_nelson.
Note how recurring parts of URLs are declared at the top with prefix directives, which saves space and improves clarity when there are many triples in a document.
Time will tell if a comparison to the human brain, where information is encoded as connections between neurons, could be appropriate. Now what if a machine doesn’t have any knowledge about one or more of the URLs it encounters? This is where the power of the “classic” Web comes in again. By dereferencing the URL—
Ontologies
Just like with regular Web documents, concepts can have many URLs, as long as one URL identifies only a single concept. Multiple ontologies can thus define the same concept (but they’ll likely do it in a slightly different way).
Related knowledge is often grouped together in ontologies, which express the relationship between concepts. For instance, the “knows” predicate on the previous page comes from the Friend of a Friend (FOAF) ontology, which offers a vocabulary to describe people and their relationships. If we dereference the URL of this predicate, we will be redirected to an RDF document that expresses the ontology using RDF Schema [18] (RDFS—
@prefix rdfs: <http://www.w3.org/2000/01/rdf-schema#>.
@prefix owl: <http://www.w3.org/2002/07/owl#>.
foaf:knows a owl:ObjectProperty;
rdfs:domain foaf:Person;
rdfs:label "knows";
rdfs:range foaf:Person.
Dan Brickley, the author of FOAF, noticed later that foaf:knows, despite its definition, became widely used for uni-directional “knows” relations; for instance, the Twitter followers of a certain person. This indicates that meaning can evolve through usage, not unlike semantic drift in natural languages.
This expresses that “knows” is a property that can occur from a person resource to another person resource. Also note the use of semicolons for continued statements about a same subject, and the predicate “a”, which is short for rdf:type. This ontology can help machines to build an understanding of concepts—foaf:Person.
The more ontological knowledge is available, the more deductions can be made. For instance, the human-readable documentation of FOAF says that the “knows” property indicates some level of reciprocity. With OWL, we can capture this as:
foaf:knows a owl:SymmetricProperty.
This would allow a machine to conclude that, if “Tim knows Ted”, the triple “Ted knows Tim” must also be a fact—
Reasoning
To make such deductions, we need Semantic Web reasoners that are able to make semantically valid inferences. Various types of reasoners exist: some possess implicit, built-in knowledge about RDF and OWL; others are designed for explicit knowledge addition. An example of the former category is Pellet [32]; examples of the latter category are cwm [5] and EYE [20]. In the context of my work, reasoners with explicit knowledge are more helpful, as they allow a higher degree of customization. Formulas enable the use of a set of triples (between braces) as the subject or object of another triple. In particular, cwm and EYE are rule-based reasoners for the Notation3 (N3) language [9], which is a superset of Turtle that includes support for formulas, variables, and quantification, allowing the creation of rules. For instance, the following rule indicates that if person A knows person B, then person B also knows person A: A rule is actually a regular triple “:x => :y.”, where the arrow => is shorthand for log:implies.
{
?a foaf:knows ?b.
}
=>
{
?b foaf:knows ?a.
}.
If we supply the above rule to an N3 reasoner together with the triple “:Tim foaf:knows :Ted”, then this reasoner will use N3Logic semantics [10] to deduce the triple “:Ted foaf:knows :Tim” from that.
As in any branch of software engineering, maximizing reuse is important for efficient development. Therefore, it is more interesting to encode the symmetry of foaf:knows on a higher level of abstraction. We can encode this meaning directly on the ontological level:
Rules for common RDFS and OWL predicates can be loaded from the EYE website [20]. They provide explicit reasoning on triples that use those constructs.
{
?p a owl:SymmetricProperty.
?a ?p ?b.
}
=>
{
?b ?p ?a.
}.
Indeed, for any symmetric property P that is true for A with respect to B holds that it’s also true for B with respect to A. Therefore, the statement that foaf:knows is symmetric, together with the above rule for symmetric properties, will allow to make the same conclusion about Tim and Ted. However, this rule can be reused on other symmetric properties and is thus preferred above the first one.
The far-reaching consequence of an open world is that no single resource can contain the full truth: “anyone can say anything about anything” [8, 28].
An important difference with offline reasoning is that Semantic Web reasoning makes the open-world assumption. Since different sources of knowledge are spread across the Web, the fact that a triple does not appear in a certain document does not entail the conclusion that this triple is false or does not exist. Similar to how the Web treats hypermedia, the Semantic Web gives up completeness in favor of decentralization and openness. This gives an interesting flexibility to knowledge representation, but also has limitations on what we can do easily. For instance, negations are particularly hard to express. Another consequence is that resources with different URLs are not necessarily different—
Agents
We might wonder to what extent Apple’s digital assistant Siri already fulfills the Semantic Web vision of intelligent agents [3]. Even though responding to voice commands with various online services is impressive for today’s standards, Siri operates on a closed world: it can only offer those services it has been preprogrammed for. Semantic Web agents would need to operate on an open world.
One of the concepts that seems inseparably connected to the Semantic Web is the notion of intelligent software agents that perform complex tasks based on the knowledge they extract from the Web. The original idea was that you could instruct your personal agent somehow to perform tasks for you online [12]. Typical examples would be scenarios that normally require a set of manual steps to be completed. For instance, booking a holiday, which requires interacting with your agenda and arranging flights, hotels, and ground transport, among other things. It’s not hard to imagine the many steps this takes, and every one of them involves interaction with a different provider. If a piece of software can understand the task “booking a holiday” and if it can interact with all of the involved providers, it should be able to perform the entire task for us.
While the initial optimism was high by the end of the 1990s—
Linked Data
On more than one occasion, Tim Berners-Lee has called Linked Data “the Semantic Web done right”.
In the early years of the Semantic Web, the focus on the agent vision was very strong and this attracted several people from the artificial intelligence community [24]. However, this also made the Semantic Web a niche topic, difficult to understand without a strong background in logics. And at the same time, the chicken-and-egg deadlock situation still remained—
Confusingly, Berners-Lee also coined the five stars of Linked (Open) Data that correspond roughly to the four principles [6].
- Use URIs as names for things.
- Use HTTP URIs so that people can look up those names.
- When someone looks up a URI, provide useful information, using the standards (RDF, SPARQL).
- Include links to other URIs so that they can discover more things.
The first principle is a matter of unique identification. Up until now, we have only talked about Uniform Resource Locators (URLs), A common example of URIs that are not URLs are ISBN URIs. For instance, identifies a book, but does not locate it. but Uniform Resource Identifiers (URIs) [11] are a superset thereof, providing identification but not necessarily location. The second principle specifically asks for HTTP URIs (thus URLs). This might seem evident, but actually, many datasets and ontologies used non-HTTP URIs in the beginning days of the Semantic Web. If we want software agents to discover meaning automatically by dereferencing, URLs as identifiers are a prerequisite. Third, dereferencing these URLs should result in representations that are machine-interpretable. And fourth, such representations should contain links to other resources, so humans and machines can build a context.
More triples do not necessarily bring more knowledge though, as humorously proven by Linked Open Numbers, a dataset with useless facts about natural numbers [35].
Since their conception in 2007, these principles have inspired many new datasets [15] and continue to be an inspiration. We are now at a stage where a considerable amount of data with an open license is available for automated consumption. Large data sources are DBpedia [16], which contains data extracted automatically from Wikipedia, and Freebase [17], a crowd-sourced knowledge base.
Linked Data is decentralized knowledge representation on a Web scale. True to the Semantic Web principles, the meaning of the data resides in its links. If a machine doesn’t recognize a URL, it can dereference this URL to find an explanation of the resource in terms of the resources that it links to. By design, no knowledge source will ever be complete, but the open-world assumption allows for this. After all, no Web page contains all information about a single topic.
The hypermedia connection
The REST principles
The semantic and REST communities tend to be quite disparate, yet their basic principles are very similar.
How does hypermedia fit into the semantics story? After all, the Semantic Web happens on the Web, the basis of which is hypermedia. If we take a closer look at the Linked Data principles, we notice that they align well with the constraints of REST’s uniform interface. To make this more obvious, let’s try to reformulate these constraints as four rules that correspond to those of Linked Data:
- Any concept that might be the target of a hypertext reference must have a resource identifier.
- Use a generic interface (like HTTP) for access and manipulation.
- Resources are accessed through various representations, consisting of data and metadata.
- Any hypermedia representation must contain controls that lead to next steps.
In REST systems, hypermedia should be the engine of application state. Similarly, on the Semantic Web, hypermedia should be the engine of knowledge discovery.
The parallels are striking, but not surprising—
A little semantics
HTML is a generic media type, as it can accommodate any piece of content, albeit with only limited machine-interpretability. The vCard format is highly specific, as it can contain only contact information, but machines interpret it without difficulty.
In REST architectures, media types are used to capture the structure and semantics of a specific kind of resource [22, 36]. After all, the uniform interface is so generic that application-specific semantics must be described inside the representation. Yet, there’s a trade-off between specificity and reusability [30]. Media types that precisely capture an application’s semantics are likely too specific for any other application, and media types that are generic enough to serve in different applications are likely not specific enough to automatically interpret the full implications of an action. Therefore, more media types do not necessarily bring us closer to an independent evolution of clients and servers.
If a machine can extract an address from semantic annotations in an HTML page, it gets the same options as with vCard.
If semantic annotations are added to a generic media type, they can provide a more specific meaning to a resource, enabling complex interactions on its content. And, as we’ll see in the next chapter, semantics can help a software agent understand what actions are possible on that resource, and what happens if an action is executed.
The phrase “a little semantics goes a long way” must be one of the most widely known within the community. (Some people like to add “…but no semantics gets you even further.”)
However, the explanation of the REST principles in the last chapter can make us wonder why we would enhance media types with semantics. Content negotiation can indeed make the same resource available in separate human- and machine-targeted representations. In practice, content-negotiation is not widespread. Part of this is because people are unfamiliar with the principle, as we almost exclusively deal with single-representation files when using a local computer. Additionally, many Web developers are only vaguely familiar with representation formats other than HTML. Finally, for many applications, human- and machine-readable aspects are needed at the same time. For instance, search engines process HTML content aided by annotations, and a browser can read annotations to enhance the display of a webpage. Several annotation mechanisms for HTML exist:
The 2012 version of the Common Crawl Corpus shows that Microformats are currently most popular on the Web, followed at a considerable distance by RDFa and finally HTML5 Microdata [14]. Perhaps in the future, the Microformats advantage will decrease, as new formats no longer emerge. The question then becomes whether RDFa and Microdata will survive, and which of them will take the lead.
- Microformats [27]
- are a collection of conventions to structure information based on specific HTML elements and attributes. Examples are hCard to mark up address data and hCalendar for events. The drawback of Microformats is that they are collected centrally and only specific domains are covered. Furthermore, the syntax of each Microformat is slightly different.
- RDFa
- or Resource Description Framework in Attributes [1] is a format to embed RDF in HTML representations. Its benefit is that any vocabulary can be used, and with RDFa Lite [33], a less complex syntax is possible. Usage of Facebook’s OpenGraph vocabulary [26] is most common [14], thanks to the incentive for adopters to have better interactions on the Facebook social networking site.
- Microdata
- is a built-in annotation format in HTML5 [25]. An incentive to adopt this format is Schema.org [13], a vocabulary created and endorsed by Google and other search engines. The expectation is that they will index publishers’ content more accurately and enhance its display if relevant markup is present [34].
While an increasing amount of semantic data on the Web is welcomed, the current diversity makes it in a sense more difficult for publishers to provide the right annotations. After all, the benefit of semantic technologies should be that you are free to use any annotation, since a machine is able to infer its meaning. However, the current annotation landscape forces publishers to provide annotations in different formats if they want different consumers to interpret them. On the positive side, the fact that there are several incentives to publish semantic annotations gives agents many opportunities to perform intelligent actions based on the interpretation of a resource.
The Semantic Web provides tools that help machines make sense of content on the Web. The Linked Data initiative aims to get as many datasets as possible online in a machine-interpretable way. Semantic technologies can help agents consume hypermedia without the need for a specific document type, improving the autonomy of such agents. There are several incentives for publishers to embed semantic markup in hypermedia documents, which aids automated interpretation. However, fragmentation issues still remain.
References
- [1]
- . RDFa core 1.1. Recommendation. World Wide Web Consortium, 7 June 2012.
- [2]
- . We knew the Web was big…. Google Official Blog, July 2008.
- [3]
- . How innovative is Apple’s new voice assistant, Siri? New Scientist, 212(2836): 24, 3 November 2011.
- [4]
- . Turtle – Terse RDF Triple Language. Candidate Recommendation. World Wide Web Consortium, 19 February 2013.
- [5]
- . cwm, 2000–2009.
- [6]
- . Linked Data, July 2006.
- [7]
- . What is the range of the HTTP dereference function? Issue 14. W3C Technical Architecture Group 25 March 2002.
- [8]
- . What the Semantic Web can represent, December 1998</span>.
- [9]
- . Notation3 (N3): A readable RDF syntax. Team Submission. World Wide Web Consortium, 28 March 2011.
- [10]
- . N3Logic: A logical framework for the World Wide Web. Theory and Practice of Logic Programming, 8(3):249–269, May 2008.
- [11]
- . Uniform Resource Identifier (URI): generic syntax. Request For Comments 3986. Internet Engineering Task Force, January 2005.
- [12]
- . The Semantic Web. Scientific American, 284(5):34–43, May 2001.
- [13]
- . Schema.org.
- [14]
- Deployment of RDFa, Microdata, and Microformats on the Web – a quantitative analysis. Proceedings of the 12th International Semantic Web Conference, October 2013.
- [15]
- . Linked Data – the story so far. International Journal on Semantic Web and Information Systems, 5(3):1–22, March 2009.
- [16]
- . Dbpedia – a crystallization point for the Web of Data. Web Semantics: Science, Services and Agents on the World Wide Web, 7(3):154–165, 2009.
- [17]
- . Freebase: a collaboratively created graph database for structuring human knowledge. Proceedings of the ACM SIGMOD International Conference on Management of Data, pages 1247–1250, 2008.
- [18]
- . RDF vocabulary description language 1.0: RDF Schema. Recommendation. World Wide Web Consortium, 10 February 2004.
- [19]
- . As we may think. The Atlantic Monthly, 176(1):101–108, July 1945.
- [20]
- . Euler Yet another proof Engine, 1999–2013.
- [21]
- . Google gives search a refresh. The Wall Street Journal, 15 March 2012.
- [22]
- . REST APIs must be hypertext-driven. Untangled – Musings of Roy T. Fielding. October 2008.
- [23]
- . Hypertext Transfer Protocol (HTTP). Request For Comments 2616. Internet Engineering Task Force, June 1999.
- [24]
- . Where are all the intelligent agents? IEEE Intelligent Systems, 22(3):2–3, May 2007.
- [25]
- . HTML microdata. Working Draft. World Wide Web Consortium, 25 October 2012.
- [26]
- . The Open Graph protocol.
- [27]
- . Microformats: a pragmatic path to the Semantic Web. Proceedings of the 15th International Conference on World Wide Web, pages 865–866, 2006.
- [28]
- . Resource Description Framework (RDF): Concepts and Abstract Syntax. Recommendation. World Wide Web Consortium, 10 February 2004.
- [29]
- . OWL Web Ontology Language – Overview. Recommendation. World Wide Web Consortium 10 February 2004.
- [30]
- . RESTful Web Application Programming Interfaces (APIs). O’Reilly, September 2013.
- [31]
- . Minds, brains, and programs. Behavioral and Brain Sciences, 3(3):417–427, September 1980.
- [32]
- . Pellet: a practical owl-dl reasoner. Web Semantics: Science, Services and Agents on the World Wide Web, 5(2):51–53, 2007.
- [33]
- . RDFa Lite 1.1. Recommendation. World Wide Web Consortium, 7 June 2012.
- [34]
- . The rise of the Web for Agents. Proceedings of the First International Conference on Building and Exploring Web Based Environments, pages 69–74, 2013.
- [35]
- Leveraging non-lexical knowledge for the Linked Open Data Web. 5th Review of April Fool’s day Transactions, 2010.
- [36]
- . REST in Practice. O’Reilly, September 2010.